The company and my role
My client produces high-value nanomaterials for research labs and medical applications. Demand was strong, but the operating model was complicated: specialized inputs with long lead times, stringent quality controls, cleanroom capacity limits, and a product mix that combined custom projects with recurring consumables.
I led the transformation of the company's FP&A process. FP&A is the Finance function that supports forecasting, budgeting, planning, and executive decision-making. The point wasn't to impress people with dashboards. The goal was more practical: help leaders make better decisions faster, using evidence, consistent definitions, and controls they could trust.
The problem we needed to solve
When the project began, 3 issues were slowing the company down and weakening confidence in the numbers.
First, next-quarter revenue forecasts were often off by roughly 15%. The misses weren't random. They tended to be too optimistic, especially when large purchase orders slipped into the following quarter.
Second, the quarterly budgeting process took about 6 weeks. Too much of that time was spent reconciling spreadsheet versions, chasing inputs, and debating definitions. By the time the budget was ready, the conversation was already looking backward.
Third, leadership didn't have a reliable way to test "what-if" questions. If executives wanted to understand the impact of adding a second cleanroom shift, a hospital pulling forward an oncology program, or precursor prices rising by 8%, the numbers had to be assembled manually. That made answers slow and assumptions inconsistent.
In plain English, the company needed to shorten the planning loop, reduce avoidable surprises, and give leaders a practical way to test decisions before making them.
What we set out to accomplish
We defined a focused set of goals tied to measures executives could audit.
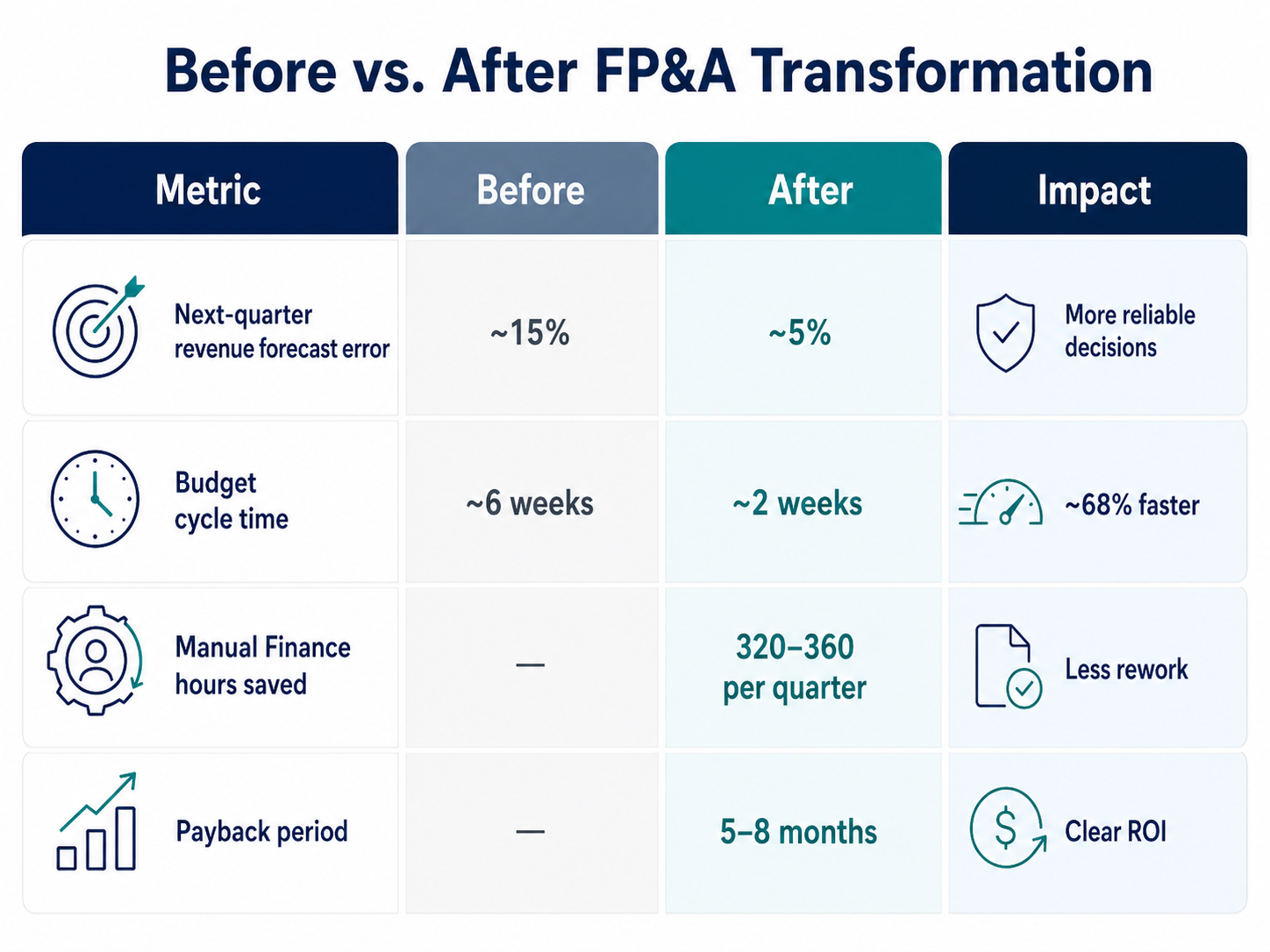
The first target was to reduce next-quarter revenue forecast error from roughly 15% to below 6%. We measured this using MAPE, or mean absolute percentage error. MAPE shows, on average, how far the forecast is from actual results as a percentage. A 5% MAPE means the forecast is typically off by about 5%.
The second target was to reduce the quarterly budgeting cycle from about 6 weeks to 2 weeks or less. Speed mattered because every week spent reconciling spreadsheets was a week not spent making decisions.
The third target was to give leaders real-time scenario analysis across revenue, headcount, operating costs, and cash. Executives needed to be able to change an assumption and immediately see the impact, with the logic clear and the version history preserved.
Governance was also built into the design. Key definitions, such as gross margin, were locked down. Access was restricted by role, often called role-based access control, or RBAC. In practice, this means people can see and edit only what their role requires, while structural model changes require approval.
What the initial diagnostic revealed
During the first three weeks, I mapped the planning process and the data that fed it. The diagnostic found 23 recurring planning files owned by 11 people. Version reconciliation alone consumed roughly one-third of the total cycle time.
Definitions were also drifting. The product taxonomy didn't match how the company actually sold and produced materials. Salesforce opportunity stages meant different things in different regions. Batch yield data arrived late, which distorted cost of goods sold.
These weren't "AI problems." They were input and process problems. Fixing them was the necessary groundwork for any analytical model to produce useful results.
The target architecture: simple, explainable, and secure
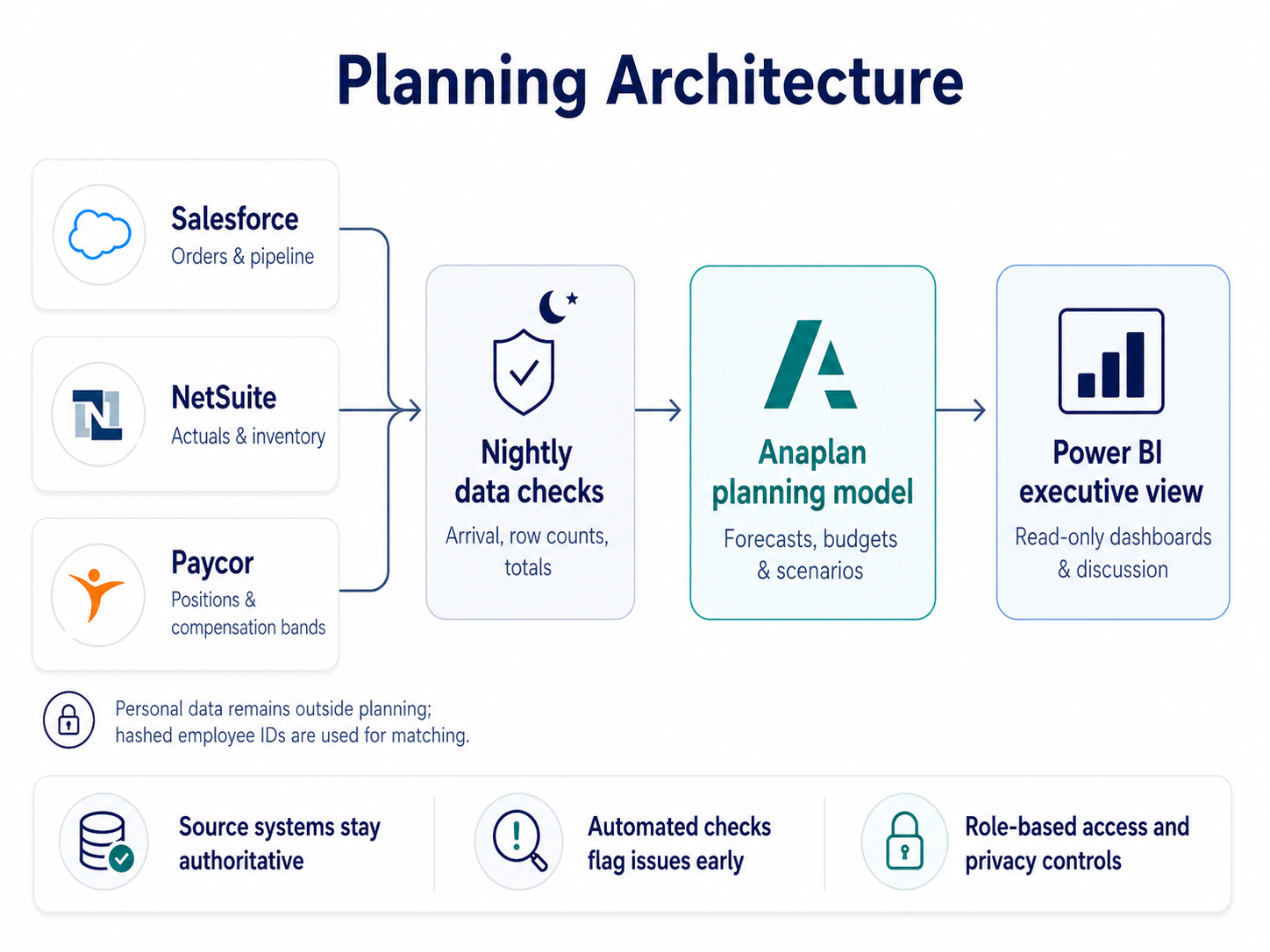
The design kept each system focused on what it did best, then connected the systems cleanly.
Salesforce remained the source for orders and pipeline: opportunities, quotes, stages, and expected close dates. NetSuite remained the source for actuals and inventory: the general ledger, inventory movements, and cost of goods sold. Paycor remained the source for people data: positions, compensation bands, start and end dates, and cost centers. Anaplan became the planning brain, where the models lived and planners ran what-if scenarios. Power BI became the read-only executive view for distribution, discussion, and decision meetings.
Data moved nightly through automated checks. Those checks confirmed that files arrived, row counts made sense, and totals matched expectations. When something looked wrong, the right owner received an alert before business hours.
Privacy was handled deliberately. Personal data from Paycor wasn't moved into planning. Instead, hashed employee IDs were used. A hash is an irreversible scramble that lets systems match records without exposing names. Compensation bands were used instead of individual pay.
How the models worked in business terms
The modeling approach avoided black boxes. Where business drivers clearly explained results, the model used those drivers. Where historical patterns were helpful, the team used straightforward, well-calibrated statistical methods.
Revenue. For new contracts, close probabilities were estimated by stage, product family, region, and deal size, using the prior eight quarters of outcomes. Calibration meant looking at what actually happened. For example, when an opportunity sat at a specific stage for a certain period of time, how often did it close on schedule? Those observed rates replaced subjective optimism.
For recurring consumables, similar customers were grouped into cohorts, such as research labs versus hospital systems, or newer buyers versus long-tenured customers. Reorder rates and price movements were then forecast for each cohort. A cohort is simply a group with shared characteristics tracked over time.
Cost of goods and gross margin. The cost model focused on unit economics: specialty inputs, cleanroom hours, energy, quality assurance, and especially batch yields. Yields in nanomaterials can fluctuate, so recent yield trends were used to estimate expected cost per unit. Capacity constraints, including equipment hours and technician shifts, were represented explicitly so scenarios couldn't assume impossible throughput.
Headcount and operating costs. From Paycor, the model used positions, compensation bands, and effective dates. This allowed for realistic hiring plans, including ramp-up periods for new scientists, vacancy factors, and attrition by location. Non-headcount expenses were tied to activity drivers. For example, quality assurance costs scaled with batch volume, and logistics costs scaled with shipments.
Scenario analysis. Executives could adjust key levers, such as adding a second shift in Cleanroom 2, slipping a hospital framework agreement by 60 days, or increasing a precursor price by 8%. The impact on revenue, margin, and cash appeared immediately. Just as important, the assumptions were named, visible, and saved, so everyone could see what changed and why.
How we implemented the transformation in 16 weeks
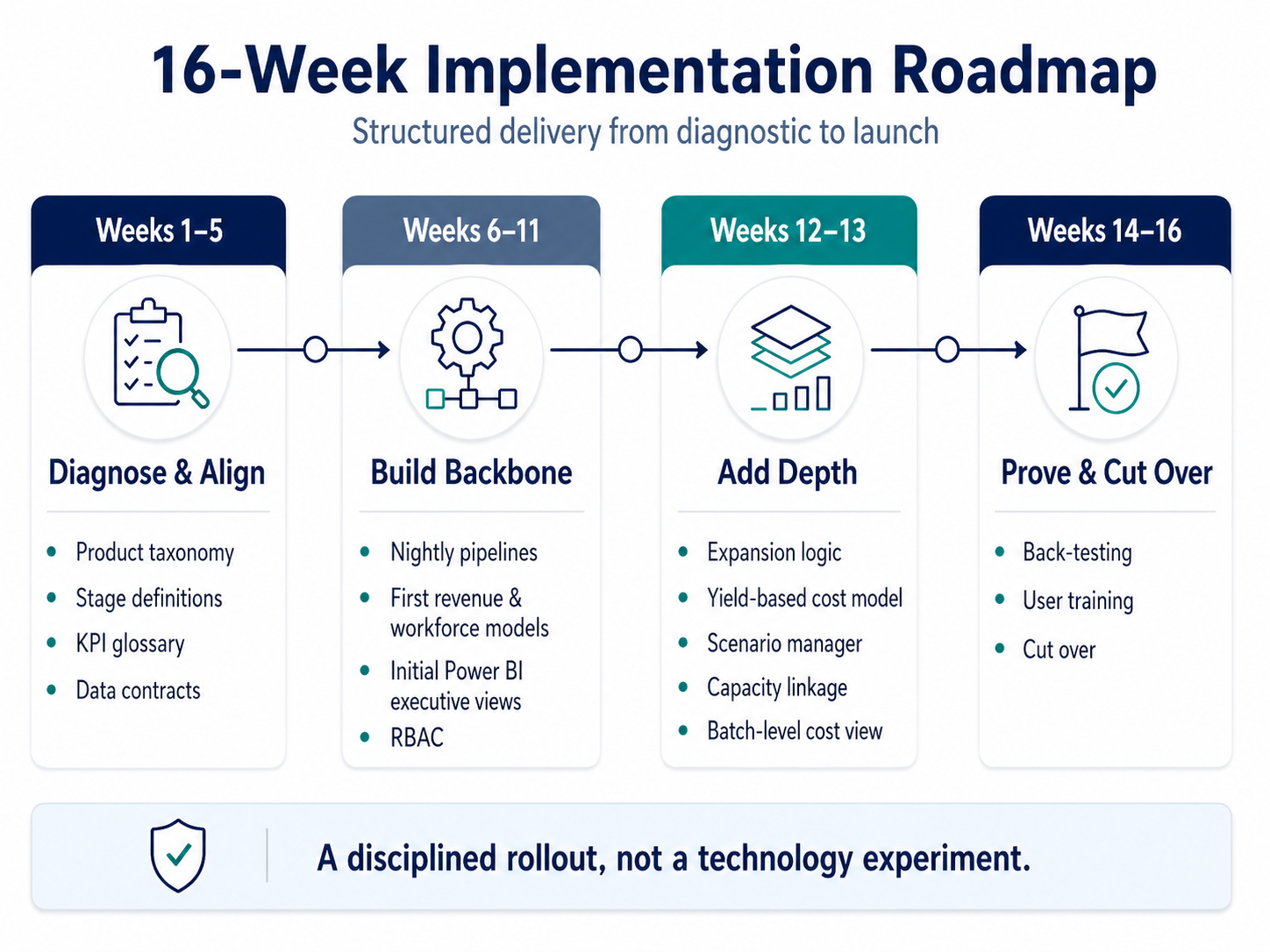
Weeks 1–5 focused on diagnostics and alignment. We fixed the product taxonomy, standardized opportunity stage definitions, and published a one-page KPI glossary so the company had a shared language. Data contracts were also agreed for Salesforce, NetSuite, and Paycor, including what would be delivered, in what format, and when.
Weeks 6–11 built the backbone. Nightly data pipelines went live. The first revenue and workforce models were built in Anaplan, and the initial Power BI executive views were created. Role-based access was also implemented so planners, reviewers, and executives saw what they needed and nothing more.
Weeks 12–13 added depth. The team implemented expansion logic for add-ons and upsells, created a yield-based cost model, and built a scenario manager that tied directly to capacity. A batch-level cost view was also added so Operations and Finance could work from the same numbers.
Weeks 14–16 proved the model worked. We ran back-tests, which means the new approach was tested against the prior six quarters to see how it would have performed. Back-testing is a useful honesty check: if the new method can't beat the old one, it shouldn't be shipped. Users were trained, and the company cut over to the new process.
What changed, and how we know
Accuracy and bias. Company-level MAPE for next-quarter revenue improved from roughly 15% to about 5%. Systematic bias, meaning the tendency to be consistently optimistic or pessimistic, tightened to plus or minus 1–2%. Renewals became more predictable once the model moved from a single uplift assumption to cohort-based behavior by customer type and tenure.
Speed and focus. The budgeting cycle fell from about six weeks to roughly two weeks, a reduction of about 68%. The biggest contributor wasn't AI. It was removing reconciliation work and enforcing common definitions, so budget meetings could focus on decisions instead of file-merging.
Capacity and adoption. The new process freed roughly 320 to 360 hours per quarter across Finance by eliminating manual consolidation and rework. Executives created and reused more than 100 what-if scenarios in the first quarter after launch, which was a strong signal that the system had practical value.
Financial impact. The direct productivity value of the time saved was about $30,000 per quarter, assuming a fully loaded labor rate of $85 per hour. More importantly, better accuracy reduced over-ordering and under-ordering, and improved the timing of hiring and supplier commitments. A conservative estimate put avoided costs and improved decisions at $150,000 to $250,000 per quarter. The full program cost, including implementation plus first-year platforms and administration, was roughly $400,000. On those numbers, payback landed between five and eight months.
What didn't work at first
The early revenue model overrated large, late-stage deals. That was corrected by calibrating probabilities separately by segment and region, and by applying a "push penalty" that reflected the historical tendency of late-stage opportunities to slip by one quarter.
The first renewal model also treated all renewals the same. That blurred meaningful differences between research labs and hospital systems. Cohorting customers by type and tenure made the forecast more realistic.
Cost data created another challenge, particularly around yields and energy. The solution was to use reliable operational proxies, such as reactor hours and batch counts, that correlated strongly with cost. Final numbers were then trued up monthly when they became available.
Governance and risk management
The system was designed so leaders and auditors could trust the numbers.
Access is controlled by role. HR planners see the detail they need. Finance sees the aggregates it needs. Structural model changes require approval and are logged. Hashed employee IDs and compensation bands keep personal data out of the planning environment.
Every plan version is named and archived. When a driver moves a key metric by more than 3%, the owner must provide a short explanation directly in the model rather than burying it in an email thread. Each quarter, assumptions are reviewed against reality, including market changes, new equipment, and updated supplier terms.
What leaders should take away
The biggest lesson is that AI-assisted FP&A works best when the fundamentals are already disciplined. Forecast accuracy improved because definitions and business drivers were fixed first. The AI-assisted layer amplified that discipline. It didn't replace it.
Speed improved because the company stopped reconciling versions and started making decisions. Scenario analysis became decision-ready. Leaders could test real options around staffing, mix, pricing, timing, and capacity, then see the impact on revenue, margin, and cash immediately, with the assumptions in plain view.